Executive Summary
Hadoop represents the circulatory and central nervous systems of “Big Data.” Despite the funny-sounding name, Hadoop is a serious enterprise software suite that enables the storage and processing of very large databases in a cluster of inexpensive servers.
Why Hadoop? We are awash in data, and the situation is likely to grow even more acute as machines, appliances and our clothing become part of the Internet of Things. Cisco Systems forecasts that the amount of Internet Protocol traffic passing through data centers will grow at a 23% CAGR to 8.6 zettabytes (that’s 8.6 x 10
21 bytes) during 2013–2018.
A Hadoop system has two main parts: a distributed file system that handles the storage of data across a cluster of servers (or nodes), and a management program that coordinates the storage of data and the running of programs within the individual nodes. A key distinction of Hadoop is that the individual nodes both store the data and handle processing in a parallel fashion. This provides redundancy of both storage and processing, so that if a server drops out, no data is lost and no processing is interrupted.
Hadoop is based on software originally written at Google, which its author reverse-engineered and altruistically made available in the public domain as open source. That led to widespread adoption by many Internet companies and enterprises. The funny-sounding name comes from the toy stuffed elephant that belonged to the son of its creator. Hadoop’s adoption built upon itself and fostered an ecosystem of Hadoop tools and add-ons. Extensions and tools for Hadoop also have odd-sounding names: Pig, Hive and HBase. A community of startups focused on expanding and commercializing Hadoop technology has also emerged. This report contains a list of 13 startups, which have raised a total of nearly $1.7 billion. One Hadoop-focused company, Hortonworks, recently raised $115 million in an IPO, and Cloudera is the next leading contender to go public, having already raised $1.2 billion.
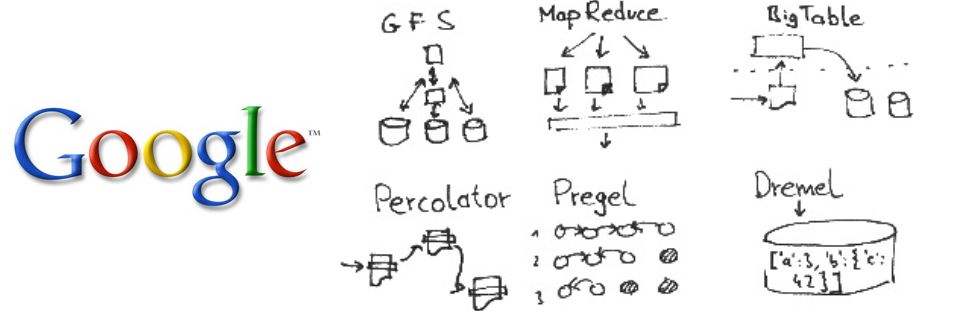
Most Internet names you know—Yahoo, Facebook, LinkedIn and many others—use Hadoop to manage their databases. Since Hadoop, founded in 2006, is getting a bit old in Internet years, other technologies—continuing the tradition of odd-sounding names such as Percolator, Dremel and Pregel—have emerged for handling large-scale databases. Interestingly, Google, the original creator of the underlying technology, has moved on to the aforementioned technologies and is therefore no longer a big Hadoop user.
Hadoop is the little yellow stuffed animal with the funny name that powers many of the Internet services we depend on today.
History of Hadoop

In the early 2000s, Google faced an immense technical challenge: how to organize the entire world’s information, which was stored on the Internet and steadily growing in volume. No commercially available software was up to the task, and Google’s custom-designed hardware was running out of steam. Google engineers Jeff Dean and Sanjay Ghemawat designed two tools to solve this problem—
Google File System (GFS) for fault-tolerant, reliable and scalable storage, and
Google Map/Reduce (GMR), for parallel data analysis across a large number of servers—which they described in an academic paper published in 2004.
At that time, Doug Cutting was a well-known open-source software developer who was working on a web-indexing program and was facing similar challenges. Cutting replaced the data collection and processing code in his web crawler with reverse-engineered versions of GFS and GMR and named the framework after his two-year-old son’s toy elephant, Hadoop.
Learning of Cutting’s work, Yahoo! invested in Hadoop’s development, and Cutting decided that Hadoop would remain open source and therefore free to use, and available for expansion and improvement by everyone. By 2006, established and emerging web companies had started to use Hadoop in production systems.
Today, the Apache Software Foundation coordinates Hadoop development, and Mr. Cutting is Chief Architect at Cloudera, which was founded in 2008 to commercialize Hadoop technology. (The Apache HTTP Server software, commonly just called Apache, is the world’s most widely used software for running web servers.)
What is Hadoop?
According to its current home,
Apache, “Hadoop is a framework for running applications on large cluster[s] built of commodity hardware. The Hadoop framework transparently provides applications both reliability and data motion.” The first part of that description means that Hadoop lets large banks of computers analyze data; the latter part means Hadoop has built-in redundancy that can recover from the failure of a server or a rack of servers, and the framework can process data that is changing over time.
Hadoop has two main parts:
- Map/Reduce, which divides a large piece of data into many small fragments; this analysis can be executed or re-executed on any node in a cluster
- Hadoop Distributed File System (HDFS), which stores data within the nodes of the cluster; this file system scheme offers high aggregate bandwidth across the cluster
Prominent Hadoop users include Facebook, Yahoo! and LinkedIn.We are awash in data, and the amount of data that needs to be processed will only get larger as the Internet of Things grows to include smart home appliances and other objects, including wearable technology that contains multiple sensors that generate reams of data. Figure 1 illustrates Cisco Systems’ forecast that the amount of Internet Protocol traffic in zettabytes passing through data centers will grow at a 23% CAGR during 2013–2018. One zettabyte is 10
21 bytes, or 10,000,000,000,000,000,000,000 bytes.
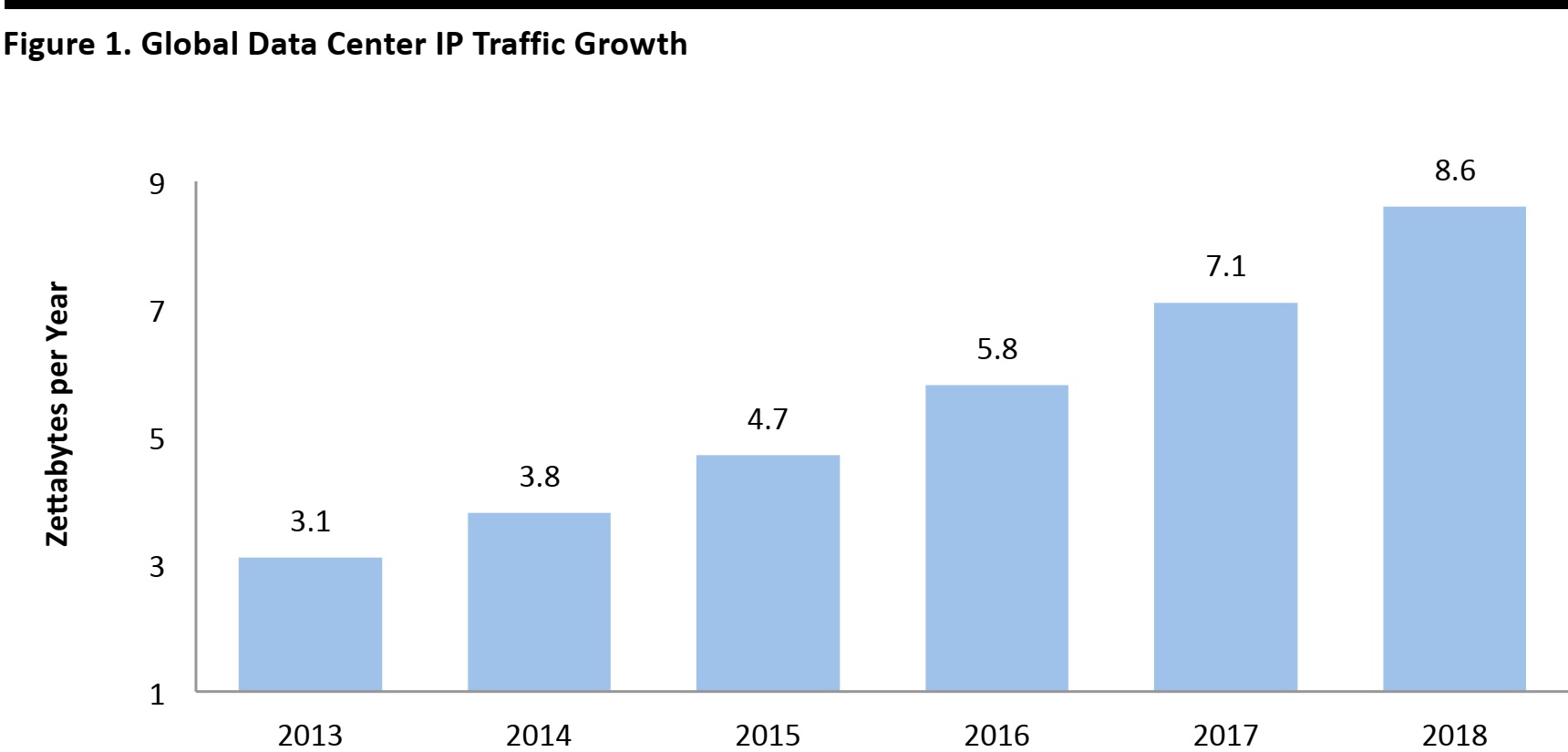
Source: Cisco Global Cloud Index, 2013–2018
The SAS Institute outlines the benefits of Hadoop:
- It’s inexpensive: Hadoop uses low-cost commodity hardware
- It’s scalable: More nodes can be added to increase capacity and processing power
- It can use unstructured data: Any data type can be used
- It employs parallel processing and redundancy: Hadoop can process multiple copies of data and redirect jobs from malfunctioning servers
Hadoop has its limitations, including:
- Other methods for rationalizing clusters with data center infrastructure are being developed
- Data security is fragmented
- Map/Reduce is batch oriented
- Its ecosystem lacks easy-to-use, full-feature tools for data integration and other functions
- Skilled Hadoop professionals are few and expensive
Technology continues to evolve, and next-generation alternatives to Hadoop are emerging. Google, the pioneer of Hadoop technology, is moving away from Map/Reduce and is embracing other technologies such as Percolator, Dremel and Pregel.
 How Does Hadoop Work
How Does Hadoop Work
Figure 2 shows the three key parts of a Hadoop cluster.
- Client Machines load data into the cluster, submit Map/Reduce jobs that describe how the jobs should be processed, and then retrieve and view the results of the finished jobs
- Master Nodes oversee data storage with HDFS and running parallel computations via Map/Reduce
- Slave Nodes store the data and run the computations
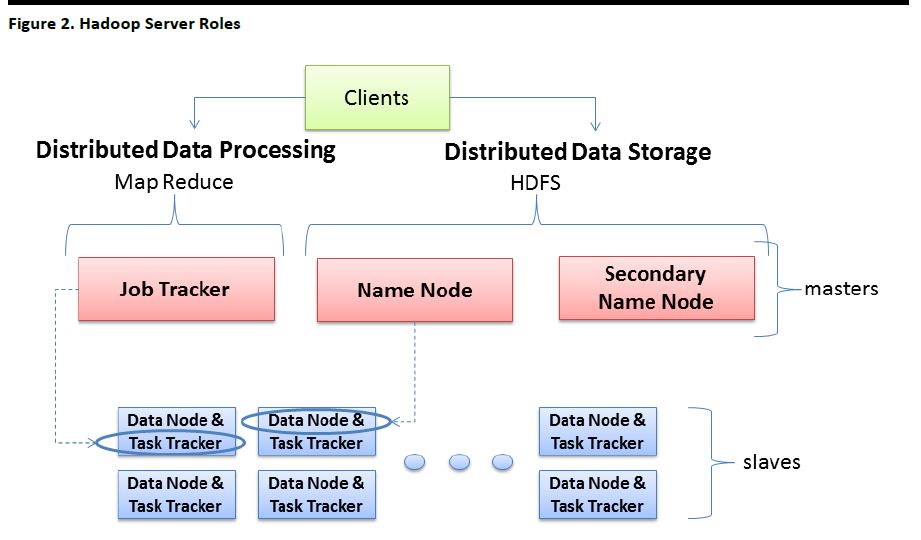
Source: BradHedlund.com
Figure 3 illustrates the Hadoop Distributed File System, which breaks up a large file into pieces that are redundantly stored on several different servers, offering the ability to recover completely from the failure of one (or even two) servers.

Source: Cloudera
Figure 4 illustrates the Map/Reduce software framework, which similarly breaks a problem into smaller pieces, which are redundantly processed, offering the ability to complete the analysis in the event of the failure of one or more servers.
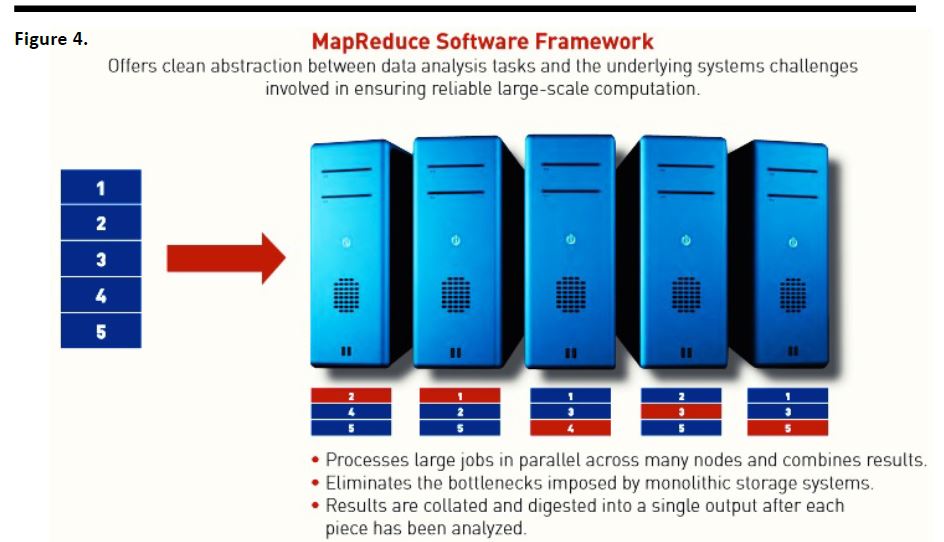
Source: Cloudera
Hadoop Components
A Hadoop setup contains the following core software modules:

More Unusual Names in the Hadoop Ecosystem — Apache Pig, Hive and HBase
The success of Hadoop has sparked an ecosystem of related software:
- Apache Pig: A high-level platform for creating Map/Reduce programs using Hadoop
- Apache Hive: A data warehouse infrastructure on top of Hadoop for data summarization, query and analysis
- Apache HBase: An open-source, non-relational distributed database written in Java

Market Opportunity
IDC estimates that the worldwide Big Data technology market—which comprises hardware, software and services—will reach $32 billion in 2017. Gartner estimates that the global data-related enterprise software market will hit $110 billion in 2018. Of this figure, startup Cloudera projects that $30 billion represents analytical workloads and operational data stores, which stands in contrast to
transactional workloads (used for analysis rather than commerce). Cloudera says that this market is the most immediately addressable by Hadoop technology, as well as one of the fastest-growing segments of the data-related enterprise market.
Who Uses It?
As of 2008, many of the world’s best-known Internet companies such as eBay, Facebook, LinkedIn, Yahoo!, and others had already adopted Hadoop as the software foundation for their big-data processing activities. Figure 6 shows the top-20 selected Hadoop users, sorted by the number of nodes. These nodes represent 90% of the more than 17,000 Hadoop nodes counted by Apache. Data for Hadoop users Amazon, Google, IBM, and Twitter were not available.
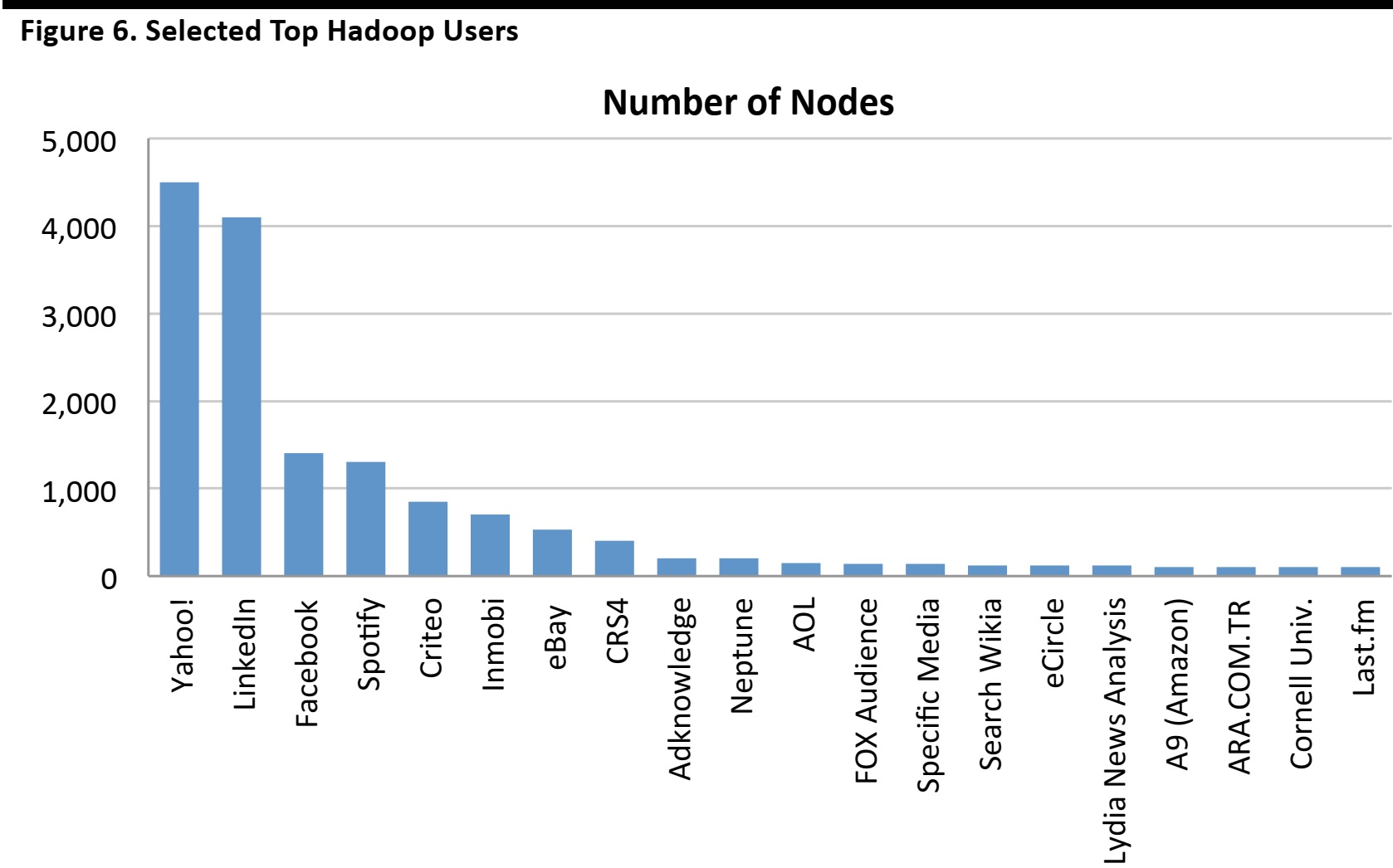
Source: Apache
Top Hadoop Technology Companies:

Source: edureka!
Hadoop Startups
Hadoop startups have been well funded by venture capitalists. Figure 7 shows selected Hadoop startups, whose funding totals nearly $1.7 billion, with Cloudera receiving more than half of the total. The company reportedly generated more than $100 million in revenue in 2014 and was recently valued at $4.1 billion.
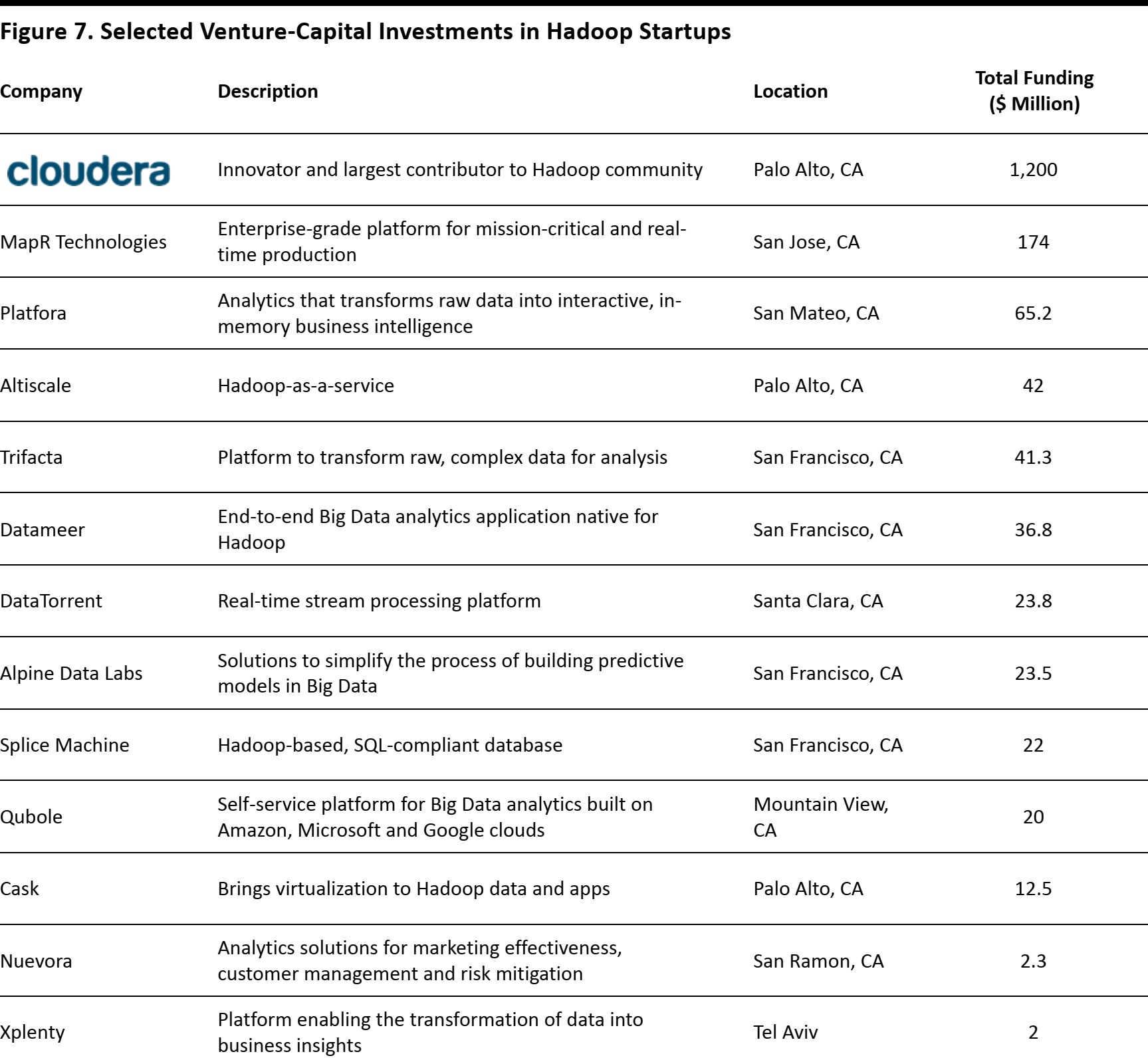
Source: CrunchBase
Hortonworks, which makes business software focused on the development and support of Apache Hadoop, raised $10p0 million in an initial public offering on December 11, 2014.
Conclusion
At the time of its introduction, Hadoop brought Google’s technology for the low-cost analysis of very large data sets on a cluster of inexpensive PC hardware to the world, thanks to its author’s history in the open-source software community. Subsequently, many Internet search engines and large enterprises adopted the software. In addition, a community developed around the software, made up of tools and startups created to enhance the technology; it has led to one IPO so far. The Hadoop community continues to thrive, even though it is somewhat aged by Internet standards and some newer alternatives have emerged. That’s quite an achievement for a piece of software named after a yellow stuffed elephant.
